Home › Forums › AWS › AWS Certified Solutions Architect Associate › Before you purchase, just know that some of these questions could be better..
-
Before you purchase, just know that some of these questions could be better..
 Carlo-TutorialsDojo updated 3 months, 2 weeks ago
3 Members
·
12
Posts
Carlo-TutorialsDojo updated 3 months, 2 weeks ago
3 Members
·
12
Posts
-

In general, I am happy with my purchase of the SAA question sets. But as someone who has been actively working in AWS for eight years and has previously had multiple certifications, I can tell you that some questions are quite frustrating. Here is what I’ve noticed on some questions:
The “Correct” answer makes assumptions about the scenario that we cannot expect the user to make. For example, the answer will need you to assume that the application is an origin to a Cloudfront distribution where in reality you can’t make that assumption and the question does not indicate how its setup.
The “Correct” answer will want you to use Route 53 failover hosting to failover to to an S3-hosted website when the primary application is down. That’s fine, but S3-hosted websites with custom CNAME do not support TLS directly (you have to setup that S3 bucket behind Cloudfront). It is not a solution to serve an insecure page.
The “Correct” answer will make assumptions that an application is being served behind a Cloudfront distribution with two origins. It will then want you to failover to the second origin if the primary fails because its being overloaded. This isn’t a solution. If the traffic is overloading the primary, then it will simply overload the secondary.
Sorry, for the long rant. I’m using the test questions to judge the areas I need to study and am finding it counterproductive to get questions unfairly judged wrong.
-
This discussion was modified 3 months, 2 weeks ago by
 Lifelong1250.
Lifelong1250.
-
This discussion was modified 3 months, 2 weeks ago by
-
Another example. Creating a KDS and sending data to it for analytics is a method for handling this but is it really the easiest or best way to handle this? And what application data are we analyzing? And if the system load is going to 100% the first thing you do wouldn’t be to create a data stream on incoming data. Unless, there is some indication that the system load is impacted by the incoming data. It asks you to make a determination without many of the details you would need.

-
Hi Warren,
Thank you for sending this question over. In relation to what you wrote earlier, we don’t just set “assumptions” for our readers. We provide relevant keywords and key phrases so the users can aptly select the most suitable answer that’s being sought after by the given scenario.
Let’s further analyze the scenario you shared:
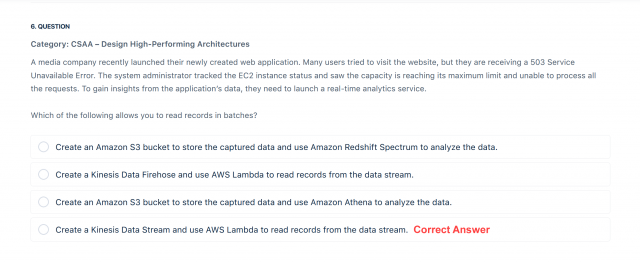
A media company recently launched their newly created web application. Many users tried to visit the website, but they are receiving a 503 Service Unavailable Error. The system administrator tracked the EC2 instance status and saw the capacity is reaching its maximum limit and unable to process all the requests. To gain insights from the application’s data, they need to launch a real-time analytics service.
Which of the following allows you to read records in batches?
KEYWORDS / KEY PHRASES:
– launch a real-time analytics service
– read records in batches
The scenario is quite clear that there is a need to launch a real-time analytics service. A “real-time” service in AWS is almost always referring to Amazon Kinesis. This is also mentioned in the provided explanation and is well-supported by the included reference to the official AWS documentation:
https://aws.amazon.com/kinesis/data-streams/
Another keyword here is “read records in batches” which is a proper use case for AWS Lambda. This is also covered in the provided explanation, as well as the AWS docs:
“Lambda reads records from the data stream and invokes your function synchronously with an event that contains stream records. Lambda reads records in batches and invokes your function to process records from the batch. Each batch contains records from a single shard/data stream.”
https://docs.aws.amazon.com/lambda/latest/dg/with-kinesis.html#kinesis-polling-and-batching
PROVIDED EXPLANATION
Amazon Kinesis Data Streams (KDS) is a massively scalable and durable real-time data streaming service. KDS can continuously capture gigabytes of data per second from hundreds of thousands of sources. You can use an AWS Lambda function to process records in Amazon KDS. By default, Lambda invokes your function as soon as records are available in the stream. Lambda can process up to 10 batches in each shard simultaneously. If you increase the number of concurrent batches per shard, Lambda still ensures in-order processing at the partition-key level.
The first time you invoke your function, AWS Lambda creates an instance of the function and runs its handler method to process the event. When the function returns a response, it stays active and waits to process additional events. If you invoke the function again while the first event is being processed, Lambda initializes another instance, and the function processes the two events concurrently. As more events come in, Lambda routes them to available instances and creates new instances as needed. When the number of requests decreases, Lambda stops unused instances to free upscaling capacity for other functions.
Since the media company needs a real-time analytics service, you can use Kinesis Data Streams to gain insights from your data. The data collected is available in milliseconds. Use AWS Lambda to read records in batches and invoke your function to process records from the batch. If the batch that Lambda reads from the stream only has one record in it, Lambda sends only one record to the function.
Hence, the correct answer in this scenario is: Create a Kinesis Data Stream and use AWS Lambda to read records from the data stream.
The option that says: Create a Kinesis Data Firehose and use AWS Lambda to read records from the data stream is incorrect. Although Amazon Kinesis Data Firehose captures and loads data in near real-time, AWS Lambda can’t be set as its destination. You can write Lambda functions and integrate it with Kinesis Data Firehose to request additional, customized processing of the data before it is sent downstream. However, this integration is primarily used for stream processing and not the actual consumption of the data stream. You have to use a Kinesis Data Stream in this scenario.
The options that say: Create an Amazon S3 bucket to store the captured data and use Amazon Athena to analyze the data and Create an Amazon S3 bucket to store the captured data and use Amazon Redshift Spectrum to analyze the data are both incorrect. As per the scenario, the company needs a real-time analytics service that can ingest and process data. You need to use Amazon Kinesis to process the data in real-time.
Regarding this statement:
And if the system load is going to 100% the first thing you do wouldn’t be to create a data stream on incoming data.
I understand your point here since there are many ways to debug, troubleshoot, and solve 503 errors in a web application. As someone who worked in the industry for 17 years, I’ve seen several production cases where doing data analytics to your incoming requests makes sense.
For instance, a web application can be inundated by illegitimate requests by several attacks that are not blocked by its existing Web Application Firewall. New cyber attacks coming from bots, Dark Web (TOR requests), Web Crawlers, and other sources require real-time analysis in order to block the source IP address, rate limit certain endpoints, or blacklist the request’s user agent.
It’s quite important to understand that the high CPU utilization is NOT always caused by legitimate user activity or a surge of requests due to mass web promotions. These spikes can be caused by internal systems (e.g. unoptimized & CPU-intensive reporting modules) and the aforementioned external attacks. At Tutorials Dojo, our learning portal has similar real-time analytics for incoming requests, as well as analytics for user clickstream.
Thus, the provided scenario is not entirely misleading or ambiguous since the provided keywords are amply included.
Let us know if you need further assistance. The Tutorials Dojo team is dedicated to help you pass your AWS exam on your first try!
Regards,
Jon Bonso @ Tutorials Dojo
-
-
Hi Warren,
Thank you for sharing your thoughts on our practice questions. We are very much open to constructive feedback, and I see that you’ve indicated three items here that you deem to have an ambiguous answer.
I understand that you have a total of 8 years working in AWS. On my end, I started working on AWS-related projects in 2014 (10 years ago) and took the first version of the AWS Certified Solutions Architect – Associate (SAA-C00) in 2018 and its succeeding versions thereafter (SAA-C01, SAA-C02, and SAA-C03). I’ve also taken several certification exams as well such as CCNA, ITIL, SCJP/OCJP and other exams in the past.
The exam scenarios in the AWS exam had various evolutions, so to speak, in the way they are designed, but one thing still remains, which is having to choose the best solution among several related options.
We don’t make deliberate “assumptions” per se since each scenario has related keywords and key phrases that support the provided answer. However, take note that the actual exam will not divulge the entire information in the scenario, and you will need to do a certain level of analysis and assumption in order to provide the best solution for the situation. It is quite concise and not as verbose as many first-time exam takers assume. This has been the style of AWS Certification exams since its 2nd iteration (SAA-C01) as someone who has been taking these certification tests on a regular basis.
The best way to discuss this is to share with us these 3 scenarios that you are alluding to here so our team and our readers can have a better context.
I’ll be waiting for the 3 scenarios, and let’s further discuss from there.
Cheers,
Jon Bonso
-
<div>OK Jon, that is fair. I want to stress that with a few exceptions, I think the questions are great. I haven’t certified in a few years so they are helping me find my weak spots. I am glad you’re responding to the post and I am going to start posting questions here so we can discuss.</div>
Question:
A company deployed a high-performance computing (HPC) cluster that spans multiple EC2 instances across multiple Availability Zones and processes various wind simulation models. Currently, the Solutions Architect is experiencing a slowdown in their applications and upon further investigation, it was discovered that it was due to latency issues.
Which is the MOST suitable solution that the Solutions Architect should implement to provide low-latency network performance necessary for tightly-coupled node-to-node communication of the HPC cluster?
<div>
</div>The correct answer is :
Set up a cluster placement group within a single Availability Zone in the same AWS Region.
(that is what I selected)But I have a question about this answer:
Use EC2 Dedicated Instances with elastic inference acceleratorNow, I know that EIA doesn’t have any impact on the solution. However, in the explanation you state:
Use EC2 Dedicated Instances with elastic inference accelerator is incorrect because these are EC2 instances that run in a VPC on hardware that is dedicated to a single customer and are physically isolated at the host hardware level from instances that belong to other AWS accounts.My question: Ignoring the EIA, wouldn’t instances on the same physical hardware provide for the lowest possible latency?
-
Hello Lifeling1250,
Let me answer your question.
Just for context, here’s the rationale that’s given for the option: Use EC2 Dedicated Instances with elastic inference accelerator
“..is incorrect because these are EC2 instances that run in a VPC on hardware that is dedicated to a single customer and are physically isolated at the host hardware level from instances that belong to other AWS accounts. It is not used for reducing latency. In addition, elastic inference accelerators only enable customers to attach low-cost GPU-powered acceleration to Amazon EC2, Amazon SageMaker instances and other resources”
EC2 Dedicated Instance indeed isolates your instances at the host hardware level. However, it doesn’t guarantee that instances will always launch on the same physical server. What it does ensure is that the underlying hardware your instance runs on is exclusively yours and not shared with other customers. Therefore, there may be situations where your instances are not colocated and are hosted on separate hardware. For that reason, the use of EC2 Dedicated Instances is incorrect.
Let me know if this helps.
Regards,
Carlo @ Tutorials Dojo
-
-
From an answer about stopping EC2 instances:
All data on the attached instance-store devices will be lost.In your opinion, how often is the term instance-store used vs ephemeral storage?
-
A question essentially asks you to figure out why you can’t get to a website on an ec2. The answer is:
** In the Security Group, add an Inbound HTTP rule.That’s true of course but simply adding HTTP port 80 is incomplete. In any common scenario you would also need to open up HTTPS (443). Would a better answer not include HTTPS rule in it?
-
Question:
An online stocks trading application that stores financial data in an S3
bucket has a lifecycle policy that moves older data to Glacier every
month. There is a strict compliance requirement where a surprise audit
can happen at anytime and you should be able to retrieve the required
data in under 15 minutes under all circumstances. Your manager
instructed you to ensure that retrieval capacity is available when you
need it and should handle up to 150 MB/s of retrieval throughput.Includes this answer as correct:
Use Expedited Retrieval to access the financial data.In explanation you say:
Expedited retrievals allow you to quickly access your data when occasional urgent requests for a subset of archives are required. For all but the largest archives (250 MB+), data accessed using Expedited retrievals are typically made available within 1–5 minutes.However, the question does not indicate the size of the archives we’re retrieving. I realize you mention 150MB/s of retrieval throughput but that doesn’t necessarily mean the archives are that size or smaller.
-
Hello Lifelong1250,
Thank you for posting this question.
Just to give our readers full context on what we’re discussing, here are the given options for this question:Option 1 – Retrieve the data using Amazon Glacier Select
Option 2 –Use Expedited Retrieval to access the financial data. (correct)
Option 3 – Use Bulk Retrieval to access the financial data.
Option 4 – Specify a range, or portion, of the financial data archive to retrieve.
Option 5 – Purchase provisioned retrieval capacity. (correct)In this scenario, the key words are:
- retrieve the required data in under 15 minutes
- handle up to 150 MB/s of retrieval throughput
When differentiating between retrieval options, the key metric is usually the access time, not archive size. I understand that there are edge cases, like the one you mentioned, where archives over 250MB may not be retrieved within 5 minutes in Expected retrieval. But in actual AWS exams, these minor details and some edge cases typically aren’t the focus when distinguishing between different options. When we write questions, we do our best to stick to the same style, wording, and format that we see in actual exams. This way, our users will get accustomed to what the real test will be like. With this said, I believe that the scenario we provided contains enough details for one to be able to pick the correct answers.
Let me know if this answers your question.
Regards,
Carlo @ Tutorials Dojo
-
-
Question: A financial firm is designing an application architecture for its online
trading platform that must have high availability and fault tolerance.
Their Solutions Architect configured the application to use an Amazon S3
bucket located in the us-east-1 region to store large amounts of
intraday financial data. The stored financial data in the bucket must
not be affected even if there is an outage in one of the Availability
Zones or if there’s a regional service failure.What should the Architect do to avoid any costly service disruptions and ensure data durability?
The answer is to enable cross-region replication on the bucket.
OK that’s fine but if you lose an entire region, and that app is only in one region then no one can access that data via the app. So really, your service is in-fact disrupted. Wouldn’t the question be better if it stated that the application is using failover DNS or even latency-based routing (with health checking) to ensure survival of lost region.
-
This reply was modified 3 months, 2 weeks ago by Lifelong1250.
-
This reply was modified 3 months, 2 weeks ago by
-
A company has a global news website hosted in a fleet of EC2 Instances. Lately, the load on the website has increased which resulted in slower response time for the site visitors. This issue impacts the revenue of the company as some readers tend to leave the site if it does not load after 10 seconds.
Which of the below services in AWS can be used to solve this problem?
Correct answers are:
Use Amazon CloudFront with website as the custom origin.
Use Amazon ElastiCache for the website’s in-memory data store or cache.
How do we know that the content isn’t dynamic on every load and therefore cannot be cached rendering Cloudfront not applicable? How do we know that the system would improve with Redis or Memcache ? Obviously there are the only two reasonable answers but they require us to make some assumptions don’t they?

Log in to reply.